
深度学习的飞速发展离不开海量数据的支撑。然而,在小样本场景中,深度学习方法的表现欠佳,这阻碍了深度学习模型在小样本场景中的应用。
近日,信息科学与工程学院人工智能与媒体计算(AIMC)实验室的王喆教授团队提出了一种基于隐式增广的方法,通过对预训练模型得到的特征表示加以重构和隐式语义增强,能够有效的减少因源域和目标域间分布差异导致的目标域特征表示偏移的问题。重构的目的是去除来自源于的噪声信息,隐式语义增强的目的是在最小化计算代价的同时令模型迅速掌握更多目标域信息。相比同类模型,该方法在小样本图像分类以及跨域小样本图像分类等各项任务中均取得了大幅性能提升。相关成果以“Better Embedding and More Shots for Few-shot Learning”为题被国际人工智能领域顶级会议IJCAI 2022(中国计算机学会推荐国际学术会议A类,CCF A类)接受,AIMC实验室博士生迟子秋为该论文的第一作者,王喆教授为通讯作者。这是近年来我校首篇以第一/通讯作者单位发表的CCF A类正文。
该研究指出,在将预训练模型应用于下游小样本任务时,对目标域特征进行拓扑重构能够缓解预训练模型潜在的对源域数据分布过拟合现象。此外,为了令目标域特征更多地捕捉目标域特有信息,可应用隐式语义增强技术丰富目标域信息。研究发现,该隐式增强方法在稳定提升性能的同时并不会引入过多计算成本,其变化仅体现在损失函数上。最后,拓扑重构和隐式语义增强二者的结合相辅相成,带来了稳定的性能提升。
本工作得到了上海市科委科技计划项目的支持。
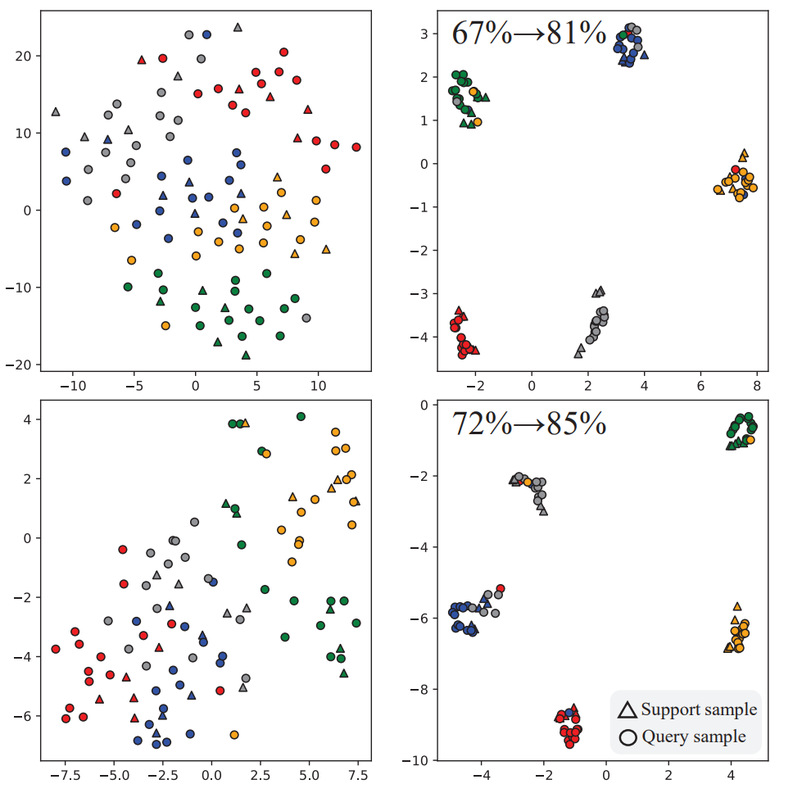
图片说明:使用该方法前后目标域特征分布的变化